
Data is the foundation of quality improvement but how much thought do we give to the biases that exist in data? To get a better understanding of data it is often useful to think about why a particular data set exists. What was its purpose and who created it? Understanding this is essential if you are going to make data-based assessments on whether quality improvement has been achieved or not.
The first stage in understanding data is seeing it as a process rather than objective truth. One method of doing this is looking at data through the Wisdom Hierarchy.
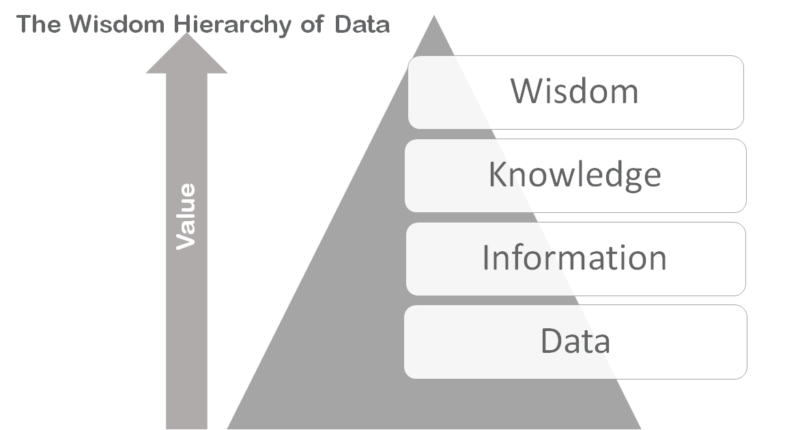
The Wisdom Hierarchy sets out that the process of data has four key elements. Progressing through the hierarchy is the thing that adds value to the work that you do. The basis of the data process is confusingly called the data layer. Within the context of the hierarchy, data is the raw data that you collect from the people that pass through your services. It has no structure and on its own doesn’t provide much value.
The information layer is where the raw data begins to have structure imposed on it. This could be creating drop-down lists, or it could be interpreting open text that has been supplied on forms. This is a key stage where bias can enter your data. Mentioning bias, in relation to data, often provokes a defensive reaction from people but is not meant to imply a level of deception in data collection.
An example of how bias manifests in the information layer can be seen through changes in social attitudes to gender. If you are working in a service that is using a ten-year-old form to record client gender it is unlikely that it will reflect a 2019 understanding of how people define gender. This is a bias that has developed through changes in social norms.
The knowledge level of the hierarchy is where the application of domain expertise, or technical processes, creates something useful out of the information. For example, applying public health knowledge to information can provide an insight that is not obvious from the original data. Analysts applying algorithms to information is another example of creating added value through knowledge.
The final stage – ‘wisdom’ – is about taking that knowledge and applying it to achieve change. The wisdom stage is the point that real value is realised and the ultimate aim of collecting the raw data in the first place. An interesting test of all data you might possess is considering how much of it progresses through the hierarchy to the wisdom stage.
The hierarchy also maps nicely onto the model of continuous service improvement and is a good starting point for any improvement process. It also highlights a potential weakness that public sector systems currently have in identifying and gathering data.
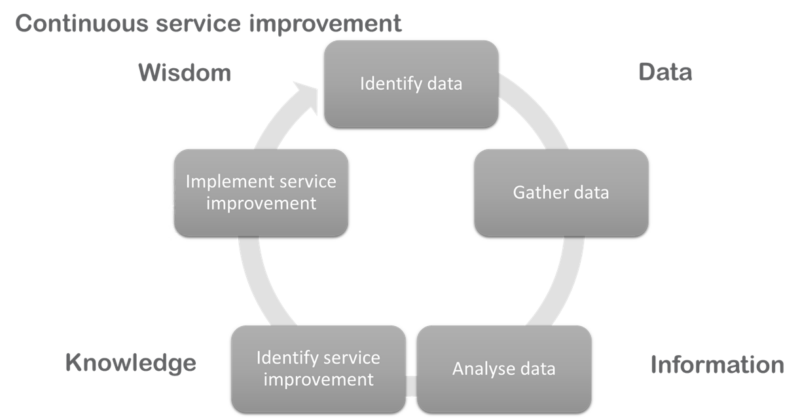
One of the key problems with using data, within the public sector, sits within the information and knowledge stages. In considering how data becomes information and is then converted into knowledge we must consider the original purpose of that data.
Much of the public sector system is a command and control system. Policy and objectives are set at the top of the system and cascade down to the frontline services. In return accountability data flows from frontline services back up to where policy is set. The purpose of this data is to demonstrate that policy is being implemented consistently throughout the system.
Accountability data is not neutral. Even within the constraints of good data management bias will enter this data as it is converted from information to knowledge. This is because the data serves two accountability purposes. It must prove the effectiveness of the service, in the context of the policy, but it also must not undermine the original basis for the policy.
An example of this can be seen in the Primary Care Quality Outcome Framework Data. This dataset is an excellent range of data, that is collected from individual GP practices and ostensibly indicates disease prevalence at a local level. But this is data that dictates an element of the payments that are made to practices and as such are open to bias. How we take account of that potential for bias in the knowledge layer dictates the value of the dataset.
The problem of accountability data is its lack of accountability. Data that is designed to prove compliance to external bodies is likely to hide failure. This is a contradiction to quality improvement where failure, and understanding its cause, is fundamental in order to identify areas for improvement.
Which leaves anyone seriously intent on achieving continuous improvement with a difficult conundrum. Collecting data solely for specific service improvement exercises will provide the most reliable data but is inefficient from a system perspective. Using readily available data and removing the bias in its creation is unlikely to be possible.
The challenge to systems is to move to a basis where the main purpose of data is not to prove that everything is working as intended. This expends a great deal of effort on an exercise that doesn’t realise value in terms of improving front line services. This is a political choice and one that is in the hands of local systems as we promote more integration.
I hope that the opportunity of integration is seen as an opportunity to realise the value of data. Breaking down the purpose of data collection is the first step of seizing that opportunity.